I wanted to see how quickly I could get a sense of the tax data in a jurisdiction. I live in Denver so I thought I’d start there.
Getting the data #
Denver.gov have an Open Data Portal so grabbing all of the real property residential data was easy.
I downloaded it and took a first look using VisiData:
| |
Converting to something useful #
It looks like there’s a natural primary key for each record called PARID.
And since I want to start using SQL to investigate the data I cranked up my favorite toolkit for this type of thing: csvs-to-sqlite, sqlite-utils, and datasette.
Loading the data is a no-brainer:
| |
I tried to add a primary key but was surprised that PARID is not actually unique:
| |
So I took a look in Datasette:
| |
Scrolling through the data in a table view with some sorting ability made me see that I definitely had duplicates for PARID.
The following query validated that there are about 20 instances where the PARID is duplicated:
| |
Kind of dawned on me that CD and OFCARD columns are probably part of a compound key.
This worked!
| |
And firing up datasette again now shows the first column as a link with all three values, indicating that the compound key is in place. Nice!
Now I can poke around the dataset using SQL.
Querying with GraphQL #
One thing I’ve studiously been avoiding is GraphQL. And yet I read that for flexible client querying it’s the way to go. REST-ful style for your primary data work (think CRUD), but GraphQL for easy downstream use.
Luckily there’s a datasette plugin for that.
| |
Now restart datasette and visit the local URL such as http://127.0.0.1:8001/graphql. For example, running this query lets me find all properties owned by out-of-state people (not Colorado), that are held in trust, and that have an assessed value in excess of $100,000. That would be a real pain to code an API for. And, I get to choose which data elements (“nodes”) to include in the results.
| |
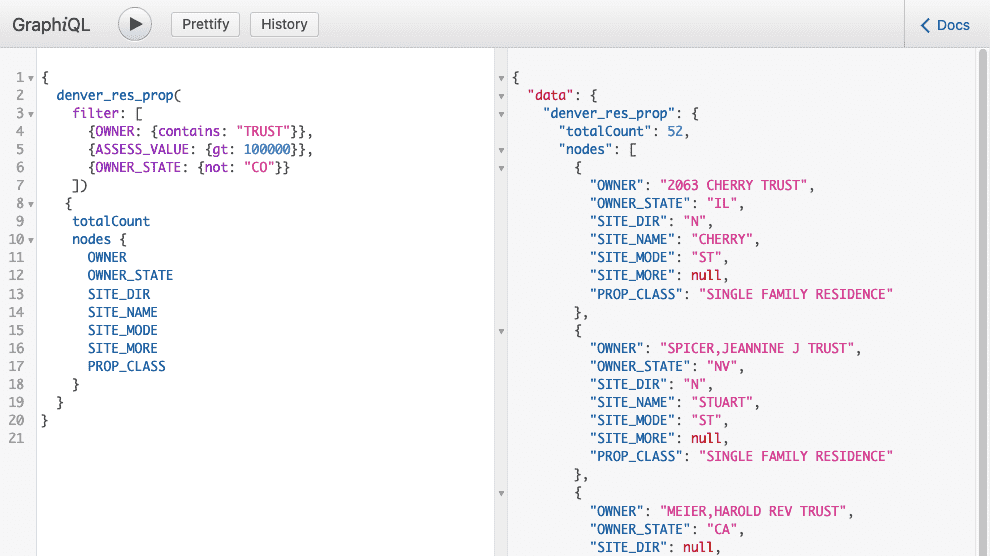
Datasette's automatic GraphQL editor
Summary #
That’s a quick look at how I can download some raw data from a public website, do a tiny bit of prep work, and have a full-featured web UI and API to poke around with the data.