I’ve poked around with Terraform before, but never forced myself to do something real. The Woolpert team I work with is all-in on Terraform for our production workloads and increasingly we start with it for client facing projects as well. As I was trying to build a small app to track my team’s professional certifications and training goals a few months ago, I thought it was time to dig in.
What is Terraform and what problem does it solve? #
Infrastructure has long been deployed using a procedure, step-by-step approach.
Just look at my own README for this project (called traintrack because I’m, well, tracking training!):
Establish an identity for the Cloud Run service to run as:
1gcloud iam service-accounts create traintrack-svc-identity
And IAM - this is one time but updatable. It can be use during a CI/CD process:
1 2 3gcloud iam service-accounts keys create \ service-key.json \ --iam-account traintrack-svc-identity@exp-traintrack.iam.gserviceaccount.com
The latter command creates a
service-key.jsonfile that is needed to deploy to Cloud Run since that’s the identity we want the service to run as. If you don’t want to run that, just use the Google Cloud Console to generate a key and save the file.
Create a global IP address:
1 2 3 4 5 6 7gcloud compute addresses create traintrack-ip \ --ip-version=IPV4 \ --global $ gcloud compute addresses describe traintrack-ip \ --format="get(address)" \ --global 34.117.190.61
That’s a whole lot of typing commands. To be sure, I prefer running these in a script over clicking a GUI but still, that’s just the first few steps of a longer process. And of course, if I goof up, I have to carefully back out of every step I’ve made and start over. It’s a really drag, this procedural approach.
Infrastructure as Code (IaC) takes a mindset that evolved in ecosystems like Kubernetes. Instead of saying how to build the infrastructure up, instead you simply declare what the end result should look like. That’s why it’s called a declarative approach over a more traditional procedural approach.
On its own, that is neat but not very compelling. Where the idea of declarative (“what not how”) infrastructure becomes a great tool is in the execution. You see, behind the scenes Terraform is actually talking to the various cloud APIs to get the job done. And the authors of Terraform providers like the Google Cloud Platform provider also write the inverse logic of setting something up: the teardown operations.
What does that mean? It means that you can define your infrastructure in a series of declarative statements (we’ll see examples in a minute) and run terraform apply.
That one command will build up the entire infrastructure in one go.
But the real magic is when you either:
- Adapt the infrastructure and retype
terraform apply. Terraform figures out what needs to change to make the current infrastructure match what you’ve declared as the desired end state, and just does it. Magic! - Delete the infrastructure, e.g., you had a test environment and you want to wholesale delete it. Just type
terraform destroyand it removes everything that it created automatically. Double magic!
This workflow is such an enormous time saver, not to mention the infrastructural equivalent of a unit testing framework.
If you try something and you screw it up, just terraform destroy then terraform apply again.
Or if you just want to make a change, terraform plan to see what is going to happen as a dry run.
And then run terraform apply.
It can seem onerous the first time you pick up Terraform as a tool, but the savings are truly phenomenal in short order.
Building the app is not Terraform’s job #
Terraform is not a build tool, packaging tool, or configuration management tool.
That’s why tech like Docker, pip, and others exist.
No, Terraform is for your infrastructure.
My TrainTrack app is really simple: just some Python packages, a Makefile to do some data prep, and a Dockerfile to bring it all together.
It uses Datasette to put a functional web interface on top of some data so I can see things like how many certifications we’ve achieved as a team:
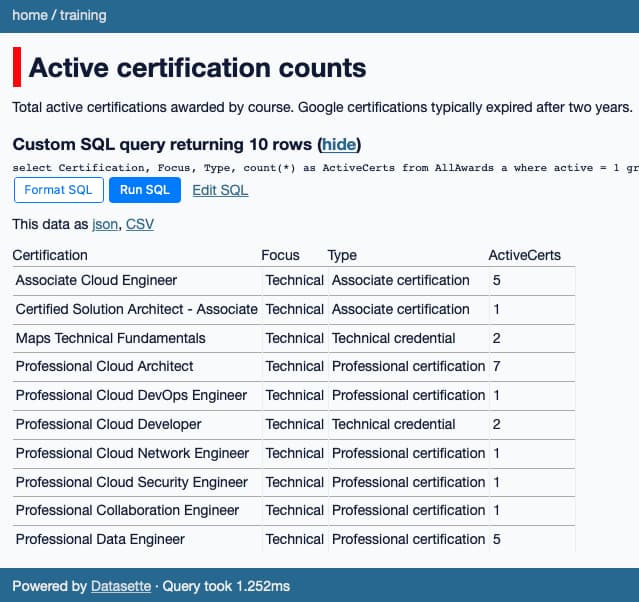
A simple way to view CSV files using SQL, courtesy of Datasette
The build and deploy process is pretty much encapsulated in this Makefile:
Makefile
| |
Hopefully it’s obvious that my choice of Google Cloud Run as a deployment platform affects how I package my app (Dockerfile built and shipped as an deployable image in an artifact repository).
Dockerfile
| |
And hopefully it’s obvious where my app build and config ends, and where Terraform will need to take over: the infrastructure to run the app on.
Picking a target architecture for the app #
Here’s a view of the infrastructure I need to deploy my app:
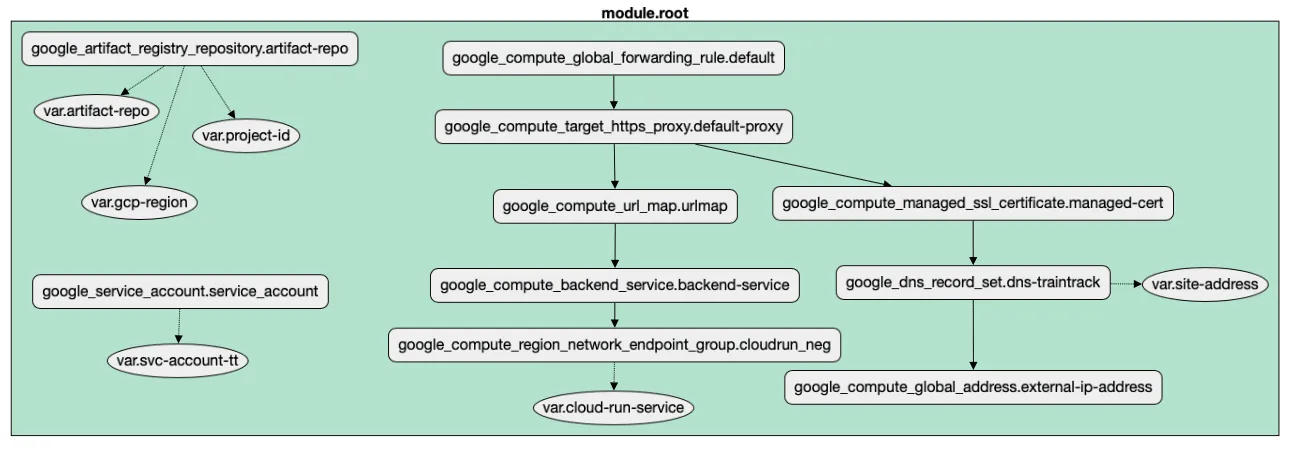
Google Cloud Run behind a load balancer and a correctly configured DNS
It’s a bit of an eye chart, so let’s break it down. I need:
A Cloud Run service. That’s where the containerized app will live, and it will be deployed on demand as I push new images to the Cloud Artifact Repository.
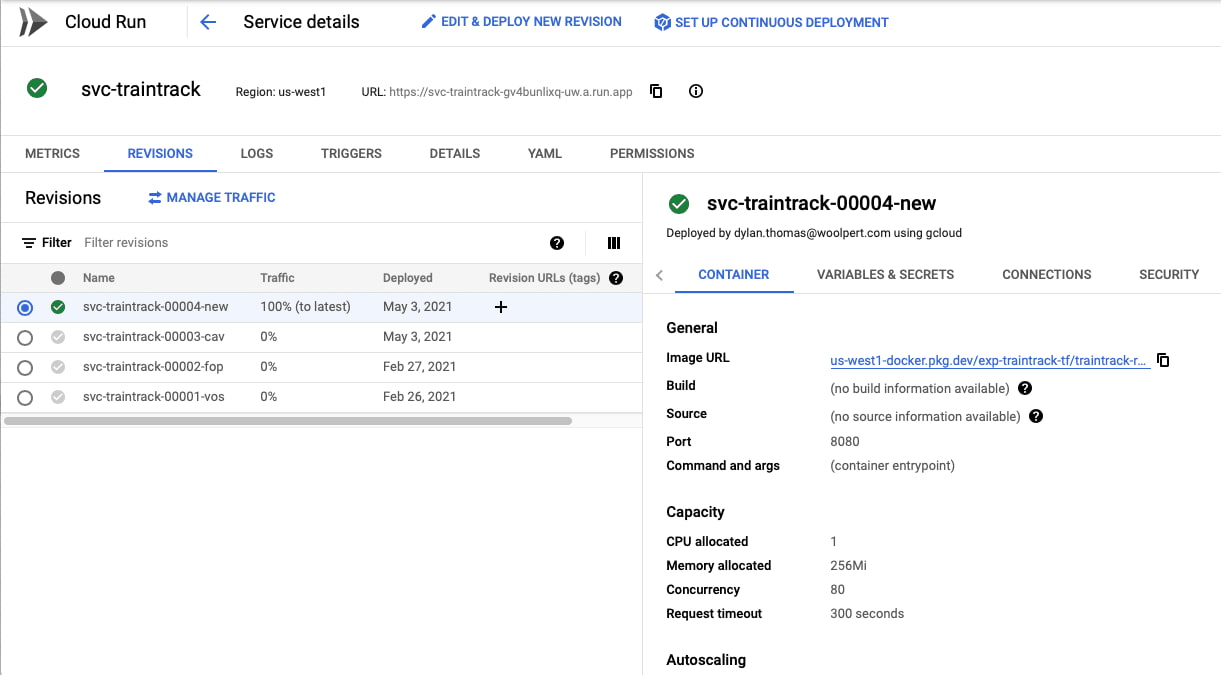
The Cloud Run service with a few revisions, tastefully named
Cloud Artifact Registry. Cloud Run will pull images from that, so I need to create one, so that I can upload docker images in the first place.
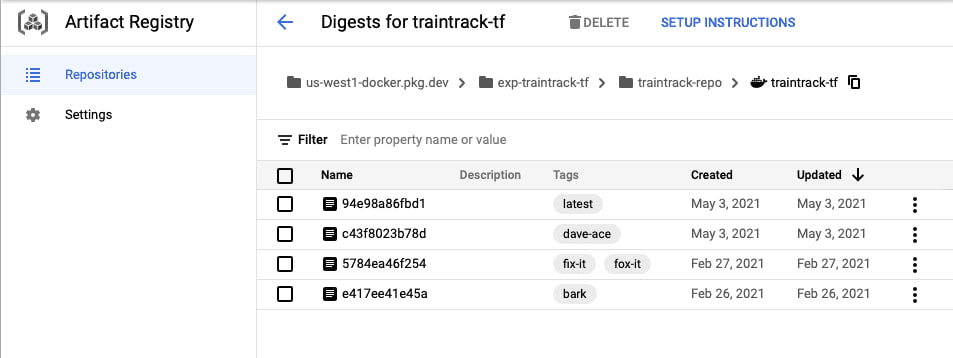
Cloud Artifact Registry is a place to keep build outputs like docker images, self-hosted package repos, etc.
All of the other elements on the diagram are needed to support the app, but aren’t especially interesting from an infra perspective. What is interesting is the interdependencies as revealed by the arrows.
- Inbound traffic to
traintrack.woolpert.iowill need a global forwarding rule which points to… - A reverse proxy that understands where to find…
- URL rewriting rules to translate from
traintrack.woolpert.iotosvc-traintrain.blahblah.a.run.app - The proxy needs to understand which External Static IP address is associated with…
- A GCP-managed DNS entry so that the traffic is all encrypted correctly, so that…
- When it gets to the Backend Service and associated Network Endpoint Group, that the request reach the correct…
- Cloud Run app instance.
So there’s a bunch of infrastructure to create. Not to mention a service account for this to all run under.
Terraform resources, variables, and values #
There are three files involved in this IaC setup:
main.tfwhich contains the definition or declaration of the infrastructure we want.variables.tfwhich defines any variables we want to use in the declarations. This helps us avoid typing the same thing twice and introducing inconsistencies.terraform.tfvarswhich are the values for the variables. This gives us separation between the declaration of the variables and their types from the values of the variables.
That last bit can sound confusing so let’s see the the terraform.tfvars:
terraform.tfvars
| |
This is our first look at some HCL which is the language that Terraform uses.
Seems pretty obvious right? Name and value declarations.
But where are these used?
First, remember the variable named artifact-repo.
Now let’s look at where those variables are actually defined, because this is not it! The declarations are in the variables.tf file.
variables.tf
| |
See the artifact-repo item there?
Yep, that’s where the variable is actually created.
It has a type (string), a helpful description, and a name.
The name is what we use to refer to the variable in other files.
The real fun begins in the main.tf where the infrastructure is actually defined.
main.tf
| |
Picking a few interesting sections…
Line 2.
stateis where tf stores its understanding of which infrastructure it has created and whether what is declared in themain.tffile has changed. In other words, does it need to make any updates?Line 6. The Google provider. HashiCorp or the cloud provider–Google in this case–write providers that wrap their specific APIs up into a series of creatable and destroyable resources.
Line 24. Here we see an Artifact Repository being defined. Remember, it’s not created here but it is defined here. We never have to worry about how it’s going to be created or managed or destroyed. We just say we want it, and TF will figure out the rest. This and many other resources have parameters. One is the provider. Others are properties like the
repository_idwhich are required by the underlying Google API. What’s interesting is the use of the variablevar.artifact-repo; that’s defined in thevariables.tffile and has a value plugged into theterraform.tfvarsfile.Line 53. Terraform manages a graph of connected resources it needs to create. Dependencies (edges) on that graph are created by having a property of one resource point to a property of another resource. In this case, the
backend.groupproperty of the backend service needs to know about (‘depends on’) the ID of the network endpoint group (NEG):google_compute_region_network_endpoint_group.cloudrun_neg.id. That means the NEG must be created before the Backend, so that the Backend can refer to the ID of the NEG. It’s a directed acyclic graph (DAG) of resources.This is another key benefit of TF: as a DAG it can optimize the creation of resources. If one resource chain does not depend on another, TF can spin them up in parallel. Look back at the diagram: in our case the artifact repository, service account, and global forwarding rule can all be created in parallel.
Building the infrastructure #
This is taken straight from the README file in the project and describes how it all comes together. Remember, the infrastructure is managed as a pre-requisite of the app, not as a build-time dependency.
Manual steps #
APIs were turned on via gcloud:
| |
Terraform #
DNS records in our corporate-resources project in order for this to work.
You shouldn’t need to touch this, but the rest of the infrastructure is defined in the infra/main.tf file.
The Terraform state is not stored in GCP in a GCS bucket because this is a toy project: it’s ok to completely
delete the project and start from scratch at any time.
That said, it’s easy to get started.
First, check that the values in infra/terraform.tfvars make sense.
Look in infra/variables.tf to understand what each one is used for.
Next, run the usual Terraform dance to validate then apply the changes.
| |
Piece of cake! And this is sooooooooo much nicer than messing about with gcloud commands and the like.
Cloud IAP #
But I don’t want this app to be available publicly. I want it to have Google single-sign on (SSO) for people at Woolpert and to be inaccessible for anyone else.
Unfortunately at the time I created the project there wasn’t a good Iac/Terraform story for Cloud Identity Aware Proxy, so I did it using the Google Cloud Console:
- Create an OAuth2 via APIs & Services > Oauth consent screen
- Create an OAuth Credential via APIs & Services > Credentials > +Create Credentials > OAuth client ID
- _Security > Identity-aware proxy.
- Check the box next to
bes-traintrack - Slide the toggle to enable IAP.
- In the slide-in window ADD MEMBER
- Add a Google group by typing the email.
- Choose Role > All roles > Cloud IAP > IAP-secured web user.
- Check the box next to
Indeed the documentation still says that this is not doable:
Only internal org clients can be created via declarative tools. External clients must be manually created via the GCP console. This restriction is due to the existing APIs and not lack of support in this tool.
Summary #
I hope a quick tour of a simple project using Terraform helps orient you with the basic concepts. Infrastructure as code, declarative infrastructure, and tools to automated it all are a great thing to add to your toolbox.