Introduction #
Find the annotated code at bytebyteai/ai-eng-projects
Complex prompts are better handled with multi-step logical answers. Reasoning models are still an LLM, but we add reasoning before the response is provided.
Current commercial models are OpenAI’s ‘o’ class models, Google’s Gemini Pro (compared to Gemini Flash non-reasoning), DeepSeek. Test GPT-4 for a quick answer vs. something like o4-mini, which is a reasoning model. It shows that it’s ‘Thinking’ and then ‘Reasoning’ content is displayed, and then the response is provided. In a run, that took about ~9 seconds. Then choosing o3, it reasons for 1m 1s, shows the code it wrote during reasoning, and printed the answer.
LLM Arena Text Leaderboard shows that the reasoning models are performing better than the non-reasoning models. 1
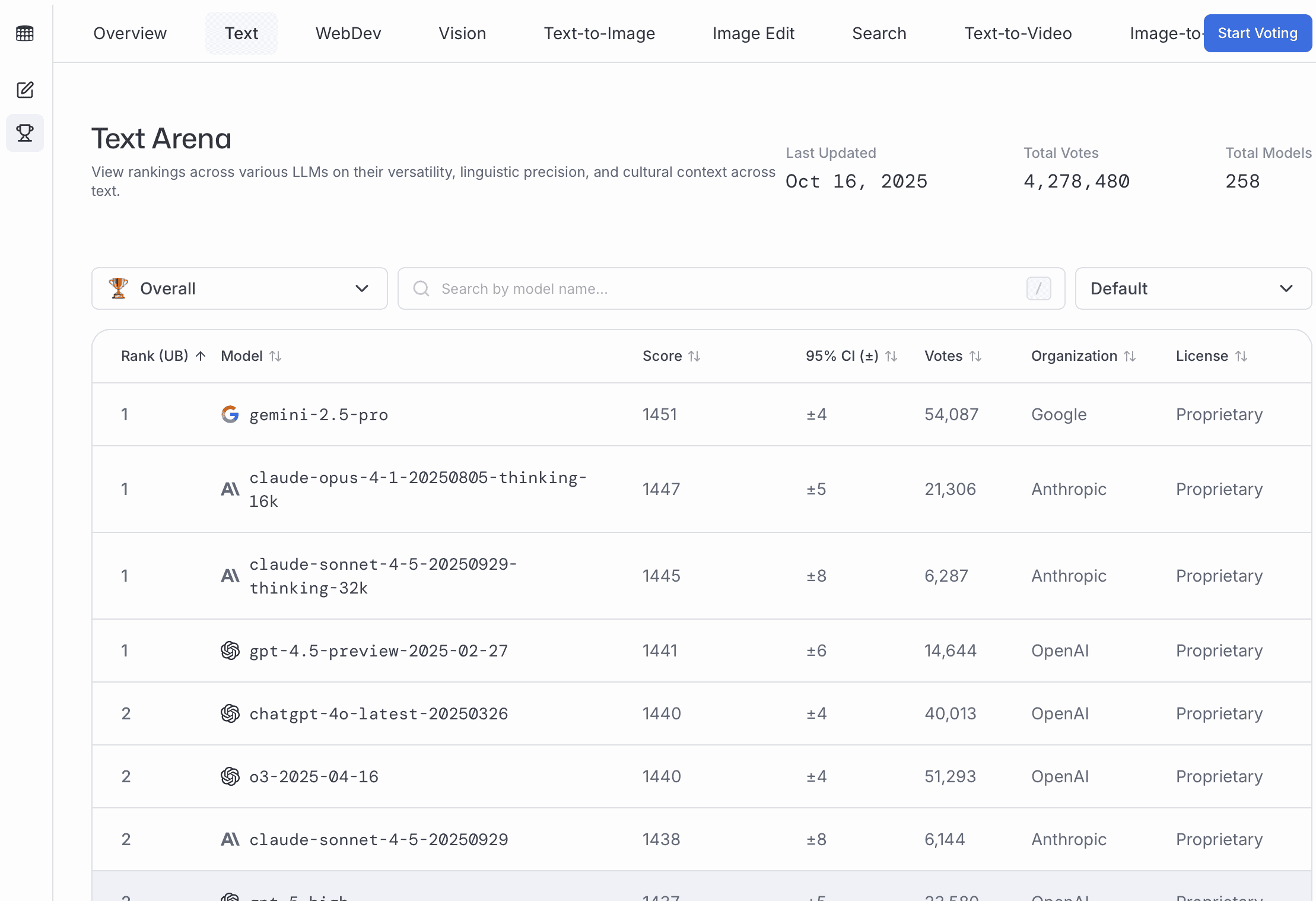
Hyperbolic's Text Arena leaderboard
As of October 2025, Kimi K2 is performing very well, and it has good technical papers. DeepSeek R1 0528 similarly has good performance, technical papers, and a very permissive MIT license.
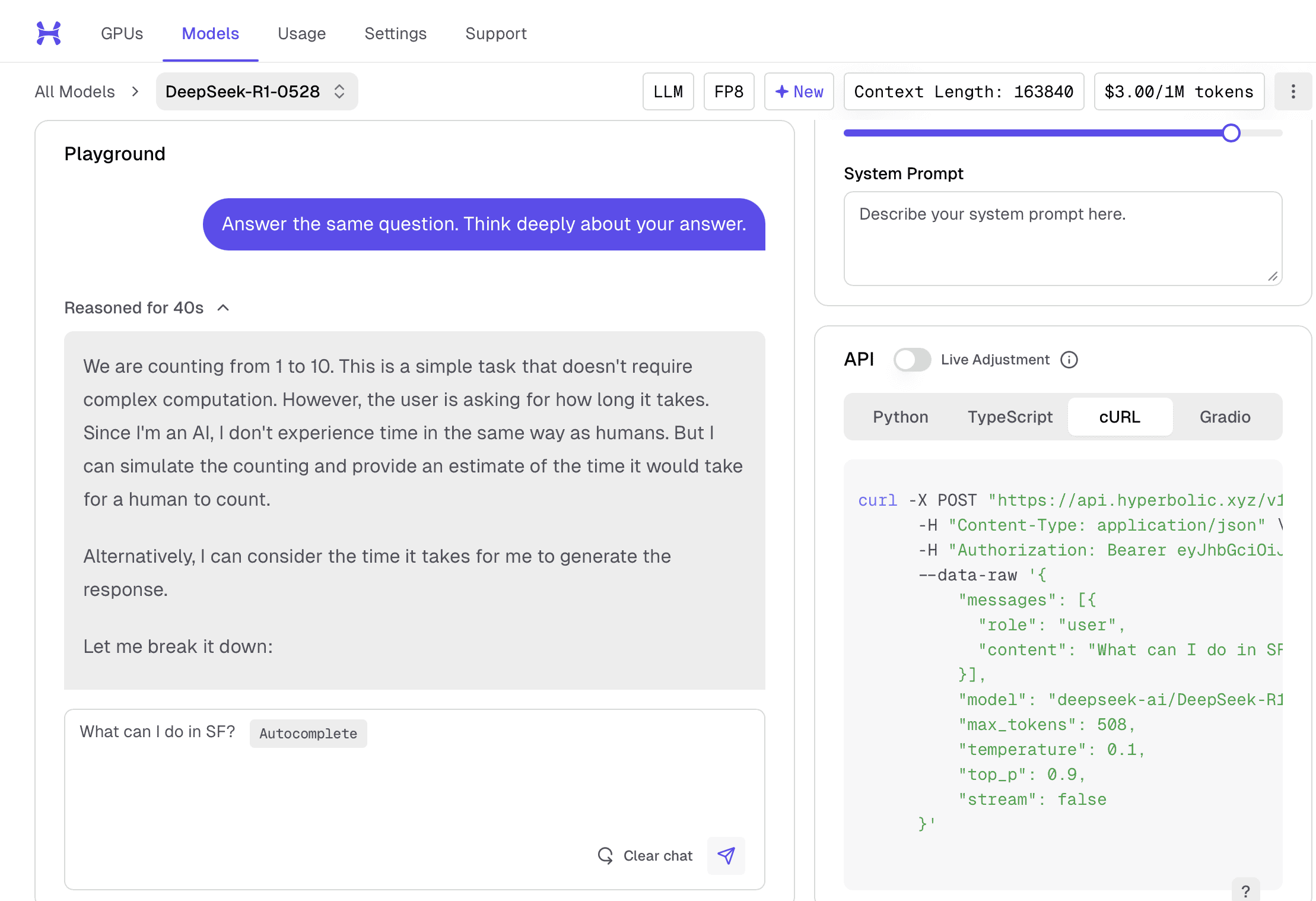
DeepSeek response showing reasoning steps
How to Build Reasoning Models #
There are two main approaches to building reasoning models, each with their own sub-classes or training:
- Inference-time Training
- CoT Prompting
- Self-consistency
- Tree of Thought (ToT)
- Sequential sampling
- Monte-carlo search
- Training-time Training
- STaR
- RL with ORM/PRM
- Meta CoT
- Internalizing search
Inference Time Training #
Chain of Thought Prompting #
The first kind is just prompt engineering. The LLM isn’t doing any multi-step reasoning.
Few shot. Notice how we’re prompting the output format with So, 6.
Example Q: There are 2 boxes with 3 balls each. How many balls are there? A: 2×3 = 6. So, 6.
Now solve this Q: There are 3 red bags with 5 apples each and 2 blue bags with 7 apples each. How many apples are there in total? A:
Model Response 3×5 + 2×7 = 15 + 14 = 29. So, 29.
Zero shot:
Q: There are 3 red bags with 5 apples each and 2 blue bags with 7 apples each. How many apples are there in total? Let’s think step by step.
Basically the LLM is processing multiple thoughts in one call:

Self consistency #
This is also called parallel sampling and best-of-N sampling. Rather than spend compute on reasoning, just get N samples from the LLM using the same prompt and then pick the ‘best’ generation during inference time.
If $N=3$ we are using some method to select $n3$ as the best (‘sample and rank’).
Google paper proposed combining both Chain of Thought and Self consistency.
The two ways to pick the ‘best’ are:
Majority Voting. Assuming that the answer is in a specific format, like our ‘So, XX.’, you can just pick whichever answer occurs the most frequently (mode).
But this only works well in certain domains like mathematics. It’s less clear for domains like writing (‘Write an article on Topic X’).
Reward Model. Assuming that the answer is in a specific format, like our ‘So, XX.’, you can just pick whichever answer has the highest confidence score.
graph TB i[Input] subgraph a [N1] a1[Node A1] --> a2[Node A2] --> a3[Node A3] end subgraph b [N2] b1[Node B1] --> b2[Node B2] --> b3[Node B3] end subgraph c [N3] c1[Node C1] --> c2[Node C2] --> c3[Node C3] end i --> a1 i --> b1 i --> c1 rm(Reward Model) a3 --> rm b3 --> rm c3 --> rm rm --> Response[Response] style rm fill:#00ffffReward models are trained on pairs of prompt and responses and is capable of generating a score—the same as training and post-training. That’s generally manual data generation with humans scoring the answers, i.e., an annotated dataset of the prompt, response, and score.
A lot of early LLMs were using this combined COT + Self-consistency.
Tree of Thoughts (ToT) #
You can think about the COT + Self-consistency as a search problem, because we’re ranking results.
So rather than run things in $N$ parallel COTs, you can create a tree instead. The tree is inherently more efficient due to pruning the tree compared to parallel runs, even though it’s less likely to produce the high quality response we’d get from COT + Self-consistency. ToT trades quality for compute efficiency.
The Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters paper has these examples worked through. The point is, there a multiple ways of trading off the quality and a tree-based search method like Beam and Lookahead.
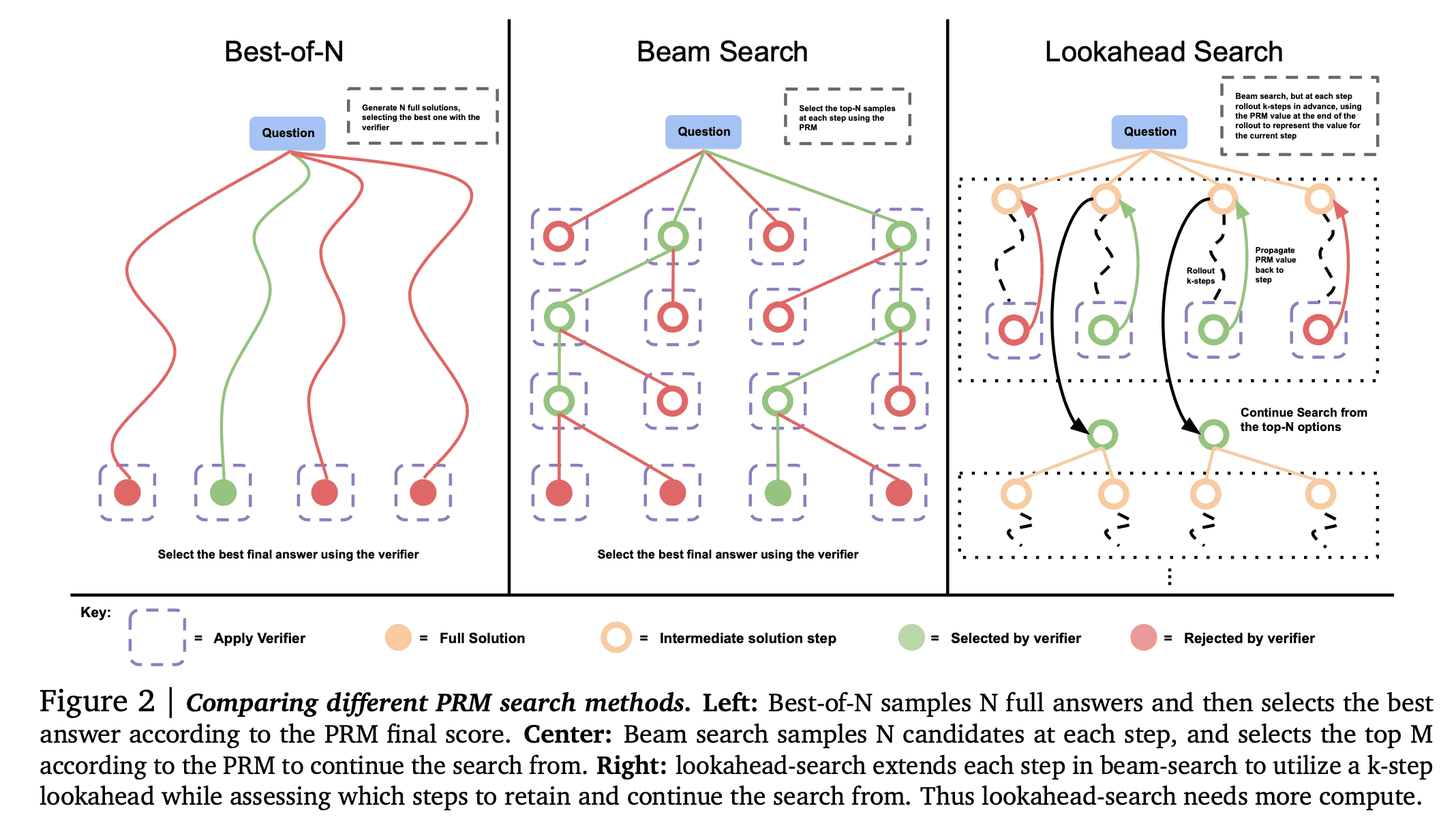
Search Methods Against a Process Based Reward Model (PRM)
Sequential Sampling #
LLMs can use external evaluation mechanisms, like a Reward Model (RM), to refine their output during the generation process. This approach is conceptually related to reinforcement learning from human feedback (RLHF) and methods that apply inference-time scaling like self-consistency. Since the Reward Model’s (RM) job is to provide a scalar score for an LLM’s output, here is minimal pseudo-code illustrating sequential sampling where the RM acts as the selector of the best response over K iterations.
The loop is what makes this interative assessment by the reward model a sequential sampling of the response.
| |
This pattern of comparing multiple generated outputs to select the highest quality one is also similar to “Voting” in parallelization workflows.
For complex problems with high difficulty, it’s very likely that that model will be pretty far off on the first attempt so parallel is better (observationally), but in practice the two approaches are very often combined.
Summary #
Inference-time scaling is trading off compute for quality and we’re not adjusting the LLM itself.
Training with Reasoning #
Many of the inference time techniques have a corollary at training time.
Train with CoT data #
Self-Taught Reasoner (STaR)
The approach described in the STaR paper shows how using questions with predictable correct answers provides the training data using a CoT approach:
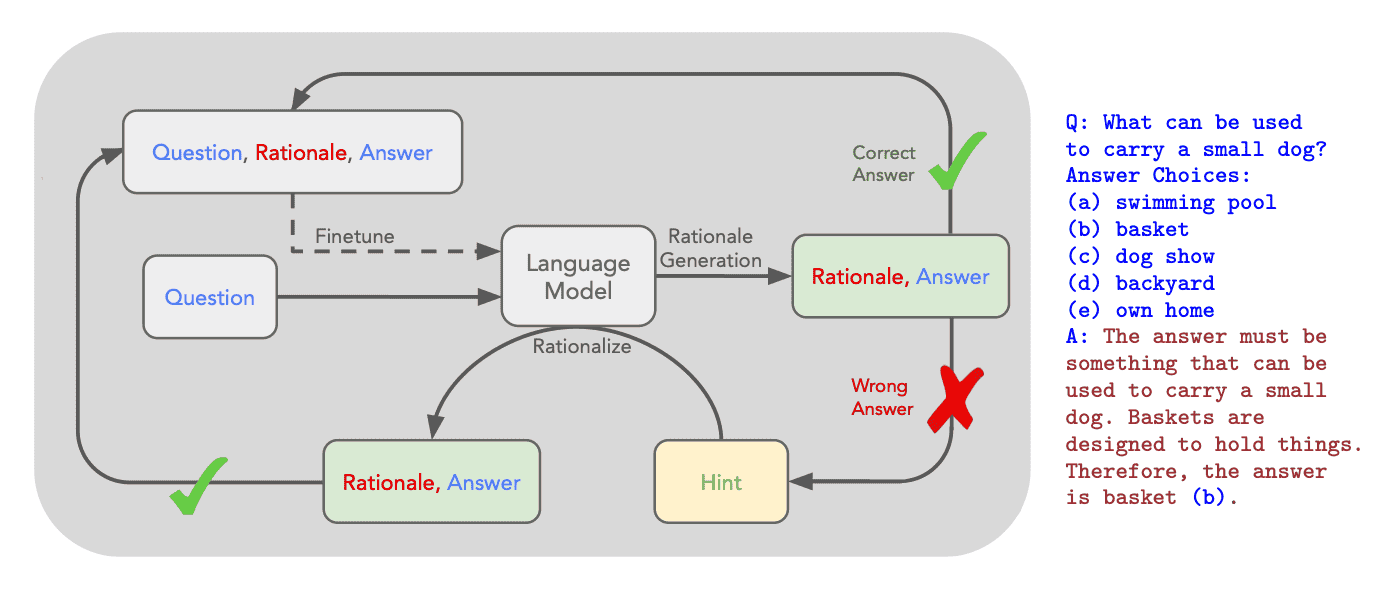
The core method from the STaR paper
So for correct answers we combine the original question with the correct answer to form training data.
For that to work we introduce special tokens like <scratch> to indicate that the LLM is in the ’thinking’ process.
When it’s done thinking it would close the </scratch> tag.
You can figure those out by either reading papers or using a site like TikTokenizer and typing words like <scratchpad> or <think> and see that the vocabulary sees that as a single token.
Reinforcement Learning with Reward Model #
Self-consistency created multiple parallel options and picked the best. The idea with RL is to continue training based on these best answers: it requires a way to reward the model for these correct answers.
During the lecture our AI Engineering instructor shared a very new (November 2025) video from Stanford on Deep Reinforcement Learning. It’s 1:45h long so I haven’t watched it yet ;-)
And for an incredibly detailed technical view of how the team building SmolLM3 made many of their decisions, there’s a HuggingFace article. This is more of a just-in-case reference because most of the details are way beyond my understanding (at this point) involving the internals of GPUs, for example.
HuggingFace’s guid for LLM Evaluation seems much more pratical.

The Outcome-supervised Reward Model (ORM) follows this pattern. Within the LLM in the above diagram, there are multiple CoT threads with intermediate steps but ORM is focused only on the final outcome.
The scores can be grades either automatically because they are deterministic (like math) or by human feedback (either offline training or realtime feedback via the application).
This is disposing of potentially useful data.
Process-supervised ORM (PRM) was proposed by OpenAI to address this loss of information.
At a high level:
| |
Where loss is the difference between the score that the the answer from the LLM achieved and the perfect score at each step, i.e., the difference.
- The primary benefit is to feed back the best answers and even interim thoughts into the LLM that is being trained so that it generates output that a human would score as ‘better’ in future.
- But there’s a second benefit of PRM algorithms, and that’s at inference time! Remember Tree of Thought (ToT) is basically a search-like function that needs a way to score each branch of the tree? Well, a good PRM model can be used by the ToT.
Self Correction #
LLM detects and revises it’s own responses in order to eventually arrive at the best possible final response. This depends on sequential revision.
Two dimensions:
- Timing
- Inference compute: Prompt-engineer! More tokens at runtime.
- Training compute: Train for better revisions.
- Source of Correction
- Intrinsic
- Extrinsic
Focus on training-time compute: we need to train the LLM for better response revisions. We need revision data to train the LLM to generate better responses. That owuld be data in the form a trajectories, typically a set of incorrect answers moving towards the correct answer.
As of 2024 self-correction through reinforcement learning (Google Brain) uses an approach called ‘SCoRe’. The details are pretty complicatione, i.e., beyond me, but here’s the basic idea after training:

Internalizing search (Meta CoT) #
(Meta Chain of Thought)system-2-reasoning is an approach to handle more complex questions. It’s not just a sequence of thoughts followed by the final answer. It’s more about trying early ‘final’ answers and then training the LLM to backtrack, try different ideas, use different data.
You can see this in thinking models with interim—or ’latent’—thoughts, backtracking to different ideas, and using different data.
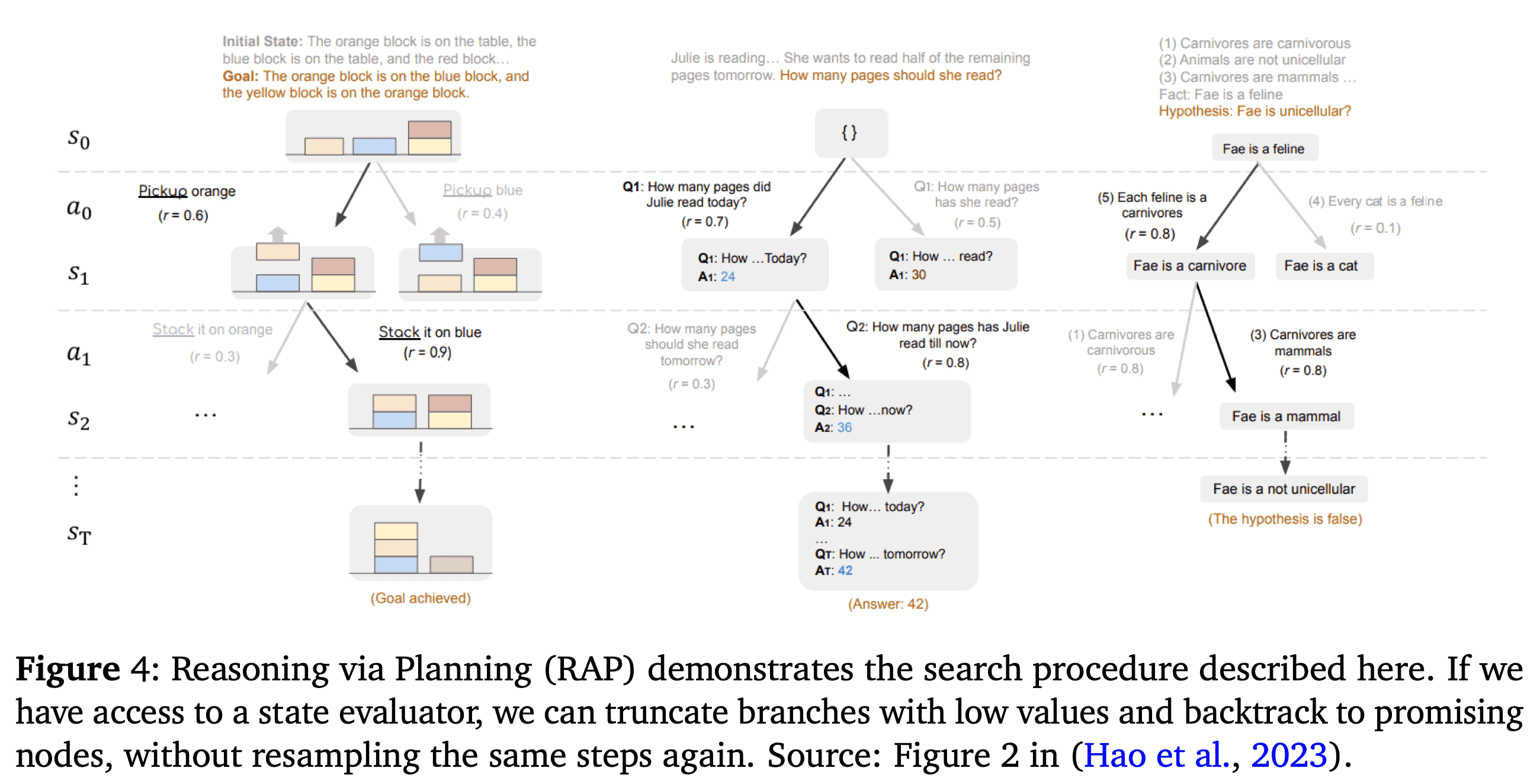
Example internal process of meta CoT
Deep Research Tool #
Deep Research extends many of the techniques from Meta CoT, including:
- Latent Thoughts: Deep Research introduces latent thoughts, which are intermediate steps that help the model explore different paths and ideas.
- Backtracking: The tool allows the model to backtrack and try different approaches when it encounters difficulties.
- Data Selection: Deep Research enables the model to select and use different data sources to enhance its understanding and generate more accurate responses.

Prompt engineering is used to push the Agent to think in models like ReACT, but now we’re able to call a Thinking LLM instead of a ’normal’ LLM.
In practice, these are multi-agent systems that looks something like this:

The Web Search Agent may in fact be different agent types, but you get the point.
Here’s an example of Claude Opus 4.1 taking a difficult task and doing prompt rewriting, stating the objective, and starting to spin up sub-agents for reseearch tasks.
Deep Research in Claude Opus 4.1
Hyperbolic.ai is a great website for testing these models. It’s not free because they have to pay for GPUs and more. Nevertheless, I threw $25 into my account and that’s been enough to experiment.
I also appreciate their tuneable parameters and the code snippets to reproduce. For example, here’s the cURL command to run the DeepSeek example:
↩︎1 2 3 4 5 6 7 8 9 10 11 12 13 14curl -X POST "https://api.hyperbolic.xyz/v1/chat/completions" \ -H "Content-Type: application/json" \ -H "Authorization: Bearer YOUR_BEARER_TOKEN " \ --data-raw '{ "messages": [{ "role": "user", "content": "What can I do in SF?" }], "model": "deepseek-ai/DeepSeek-R1-0528", "max_tokens": 508, "temperature": 0.1, "top_p": 0.9, "stream": false }'