Introduction #
I’ve been building CalcMark on and off for about four months now. It’s a calculation language embedded in markdown—you write prose, and any line that looks like math gets evaluated in place. Variables carry forward. Units and currencies just work.
# Monthly Budget
income = $5000
rent = $1500
savings_rate = 20%
savings = income * savings_rate
remaining = income - rent - savings → $2,500.00
The language runs everywhere: a TUI editor in your terminal, a web playground, a VS Code extension, and a CLI that plays nicely with pipes. Multiple front-ends, one interpreter. About 400 Go source files and 228 test files.
Visit CalcMark Lark if you want to try it live online.
I’m writing this post because I couldn’t find much practical advice about building a language when I started—lots of theory, not many war stories. These are the lessons I wish someone had shared with me before I began: the design tradeoffs, the silent failures, the Go-specific gotchas that only show up once you’re deep in it.
I had help #
I didn’t hand-write this code. Claude wrote 98% or more of it1. I directed every feature, made every design decision, reviewed every diff, scoped every test expectation, and debugged every confusing failure. But the actual Go? That’s Claude. What I did do is learn a tremendous amount about language design by steering the whole thing—and this post is about those lessons.
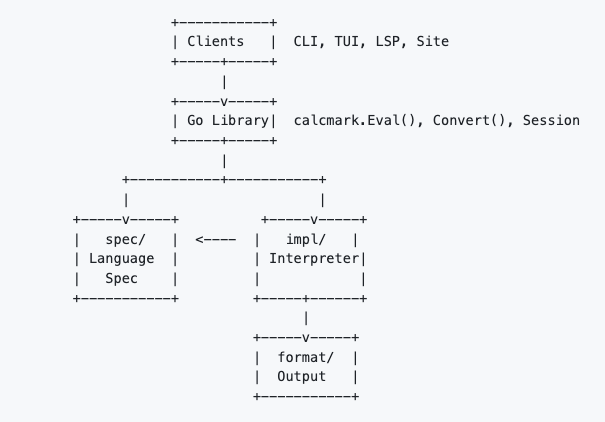
The architecture #
Before getting into the lessons, it’s worth understanding how CalcMark is structured—because most of the bugs and tradeoffs below only make sense in context of the layered design.
CalcMark is organized into four layers with a strict dependency rule: the language specification never imports the implementation. If someone ever wanted to write a CalcMark interpreter in Rust or Python, they could use the spec/ packages as a reference without even looking at the Go interpreter.

The spec/ layer defines what CalcMark is—grammar, AST2, type definitions, semantic rules.
| |
The evaluation pipeline #
Every CalcMark expression flows through four stages—three in spec/, one in impl/:

Each stage produces typed output that feeds the next:

Textbook interpreter design. It earns its keep every time we change one stage without breaking the others.
But knowing the theory doesn’t protect you from the practice. And the practice…well, the practice is where I learned everything worth writing about.
Lesson: every new type touches eight layers #
In a layered architecture, a “simple” new type is a cross-cutting concern. Miss any layer and you get silent failure, not an error.
CalcMark supports fractions—1/2, 3/4, 11 3/8 inches. Adding them seemed straightforward. It wasn’t.
A new type has to be recognized at every layer:
- Type definition (
spec/types/) - Lexer—recognize
1/2as fraction syntax, not division - AST—nodes for fraction literals and mixed numbers
- Parser—parse
1/2and11 3/8into those nodes - Classifier (
spec/classifier/)—know that1/2alone on a line is math, not prose - Semantic checker—validate fraction operations
- Interpreter—do the arithmetic
- Formatters—display correctly across HTML, JSON, Markdown, plain text
Miss any one and you don’t get an error. You get silent degradation.
When we forgot the classifier, lines containing only fractions fell through as markdown prose. They just disappeared. No error, no warning.
The formatter had its own quiet failure in format/display/formatter.go:
| |
That v.String() fallback bypasses the FormatQuantity() pipeline where unit normalization happens. So 287 1/2 pints displayed literally instead of auto-scaling to ~36 gal.
And units on mixed numbers: 12 1/2 pints lost its unit entirely. The binary addition in impl/interpreter/operators.go uses “first-operand-wins” for units:
| |
The 12 (no unit) was the left operand. No unit to win. 12 1/2 pints became 12.5.
The tradeoff: Layered architecture buys you isolation; the cost is coordination. A “simple” addition like fractions touches 20+ files. I’d make the same choice again, but I underestimated the coordination cost by a lot. The fix was a mandatory 8-layer checklist that Claude reads before starting any type work.
Lesson: Go maps will betray you #
In a language implementation, order almost always matters. Default to ordered data structures—retrofitting is painful.
CalcMark lets you define variables in a frontmatter block:
---
exchange:
USD_EUR: 0.92
USD_GBP: 0.79
globals:
tax_rate: 0.08
discount: 0.15
---
price = $29.99
tax = price * @globals.tax_rate
euro_price = price in EUR → €27.59
The TUI editor has a test for editing this frontmatter. It passed sometimes and failed sometimes. Completely at random.
Go maps have intentionally non-deterministic iteration order. The frontmatter stored variables in maps, and code like this was scattered everywhere:
| |
The order of name, rate changes on every execution. I realized what was happening and had Claude grep for all map iteration sites. Eighteen. Across 15 files. So…that was a fun afternoon.
The fix added ordered key slices alongside each map in spec/document/frontmatter.go:
| |
| |
Keep the map for O(1) lookups, iterate the slice for deterministic order.
The tradeoff: In a language implementation, order almost always matters—for deterministic output, for test stability, for user expectations. Default to ordered structures. Retrofitting is painful.
Lesson: dual syntax means every bug is two bugs #
If your language has two ways to express the same thing, every bug is two bugs. Build parity tests that verify both forms produce identical output.
CalcMark supports both functional and natural language syntax:
compound($1000, 5%, 10, monthly)
compound $1000 by 5% monthly over 10 years
Both should produce $1,647.01 (monthly compounding). Both produced $1,628.89 (annual). Same wrong answer, two completely different code paths.
The functional path in impl/interpreter/growth_functions.go only recognized frequency modifiers with a compounded: prefix:
| |
The bare identifier monthly didn’t match isFrequencyAdverb() yet, so freq stayed empty. No error. Just the wrong answer.
The natural language path had its own bug. parsePrimary() greedily consumed monthly as a unit suffix on the percentage:
| |
5% monthly became a QuantityLiteral with unit monthly. The NL compound parser never saw the frequency modifier.
I scoped out “cross-syntax parity tests” and had Claude implement them in nl_equivalence_test.go:
| |
These tests have caught four more bugs since we added them.
The tradeoff: Dual syntax means two code paths that must stay in sync. The architectural response was a single feature registry in spec/features/registry.go:
| |
One registry drives help text, autocomplete, documentation, and parity tests. The catch-all fallthrough anti-pattern has been banned. Unrecognized input must error, never silently degrade.
Lesson: when state forgets everything #
For stateful components, use pass-by-reference so there’s one source of truth. If your app “forgets” cursor position or user input, value-based state passing is the first place to look.
CalcMark’s TUI editor has autocomplete—start typing a variable name and it suggests matches. The suggestions should be scope-aware: if you’re on line 5, you should only see variables defined on lines 1 through 5.
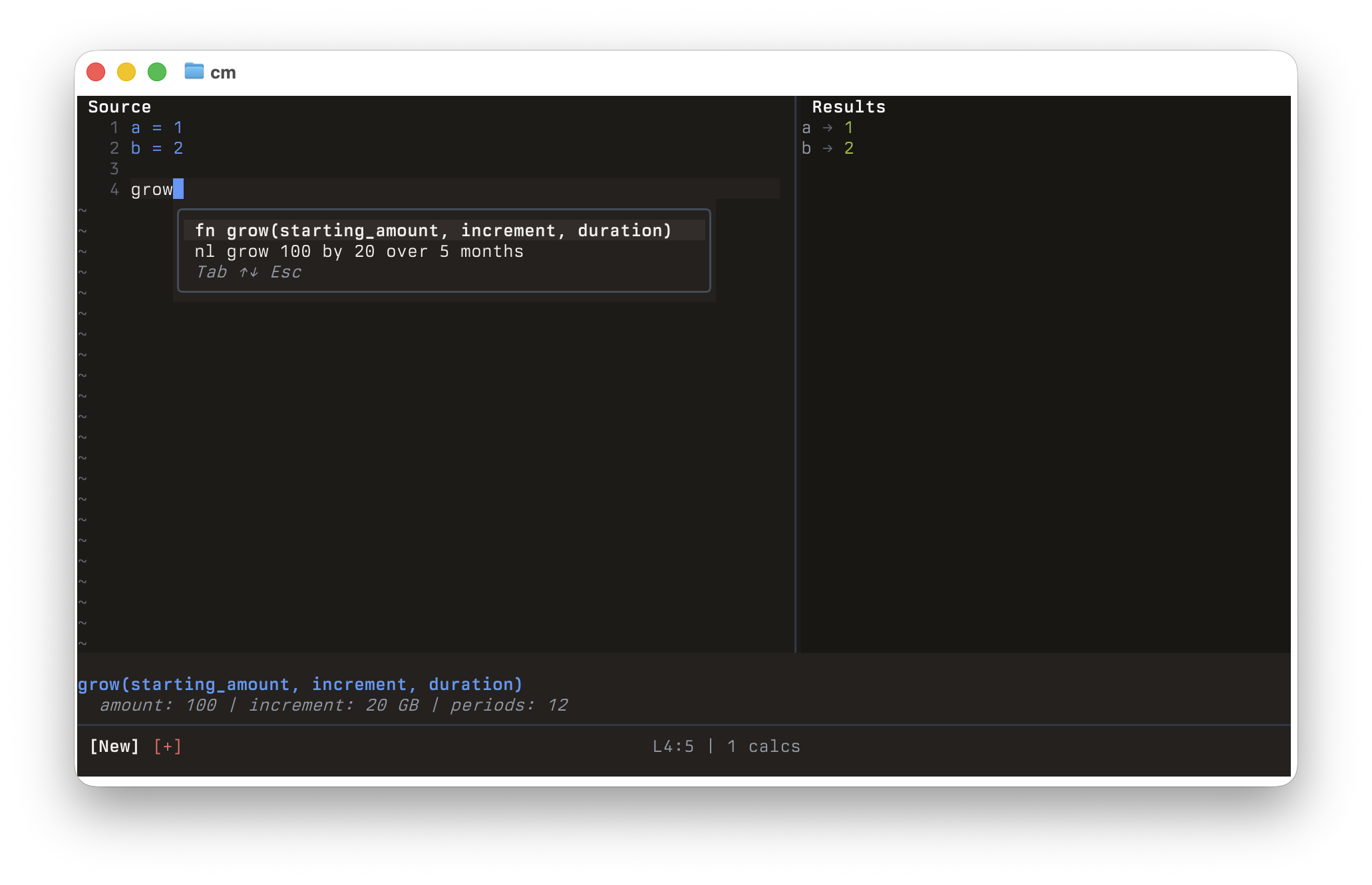
Autosuggest must know exactly where the cursor is on every keystroke
But the autocomplete was always suggesting variables as if the cursor was on line 0. Write a 30-line document, scroll to the bottom, start typing, and the suggestions showed nothing—because no variables are defined before line 0.
The root cause in cmd/calcmark/tui/editor/model.go: the editor’s Model struct holds all state—cursor position, variables, evaluation results. In Go, structs are value types. The constructor created a Model, wired up components that referenced it, then returned a copy:
| |
After return m, there are two Model instances: the caller’s copy (updated as the user types) and the original (which the suggestion source still references, frozen). The app was updating one and reading from the other.
The fix was passing state by reference—one Model, one pointer, one source of truth. Two days later, Claude caught the same pattern in an AlignedModel cache because the first fix was in a solution doc.
The tradeoff: Go defaults to pass-by-value, which prevents accidental mutation. But for stateful components, you want the opposite: one central source of truth, passed by reference. If your app seems to “forget” things—cursor position, user input, computed values—value-based state passing is a good place to start looking.
Lesson: the classifier is always the layer you forget #
If your language is embedded in another format, you need a layer whose entire job is to ignore everything that isn’t yours. That layer is easy to forget because it’s not on the “happy path.”
CalcMark is more like a Jupyter notebook than pure Python—a mix of markdown prose and executable calculations in one document:
# Trip Budget ← markdown
miles = 340 ← calculation
gas_price = $3.29 ← calculation
This is going to be expensive. ← markdown
fuel_cost = miles / mpg * gas_price ← calculation
The classifier decides which is which. Here’s the core of ClassifyLine:
| |
It sits outside the main pipeline—a gatekeeper that runs before lexer→parser→semantic→interpreter. And I keep forgetting to tell Claude to update it.
When we added @directive references, Claude updated six layers. All working. But the classifier had no awareness of @ tokens, so @scale on its own line was classified as markdown. The pipeline never saw it. Same thing happened with fractions. You’d think I’d learn.
The interpolation system had the same blind spot. Here’s the regex from impl/document/interpolation.go:
| |
The original regex was just \w+. This document silently broke:
---
globals:
tax_rate: 0.08
---
price = $29.99
tax = price * @globals.tax_rate
Tax is {{@globals.tax_rate}} on a price of {{price}}.
{{price}} worked—price matches \w+. But {{@globals.tax_rate}} has @ and ., which \w doesn’t match. The output rendered the literal text {{@globals.tax_rate}} instead of 0.08.
The tradeoff: The classifier exists because CalcMark is a mixed-format document. Every new syntax form has to be registered in a layer that’s easy to forget because it’s not on the “happy path.” Our mitigation: a pair of checklists Claude reads before cross-layer work—an 8-layer checklist for new types and a 12-layer checklist for new expression forms, both with the classifier called out explicitly.
Lesson: reject bad input at the gate #
A language that accepts arbitrary user input needs hard limits enforced before expensive work begins.
CalcMark takes user input and parses it. That means someone can write (((((((((((( 150 levels deep, or x1+x2+x3+...+x10000 as a token bomb, or compound($1, 1%, 999999999) to burn CPU on a huge exponentiation.
The parser enforces limits in spec/parser/limits.go:
| |
These get checked before parsing starts. The nesting depth uses an enterDepth()/exitDepth() pattern in the recursive descent parser:
| |
We also hit a fun one where YAML’s .nan and .inf values in frontmatter caused decimal.NewFromFloat() to panic. A user could write this:
---
scale: .nan
---
price = $29.99
The fix was a guard at the boundary:
| |
The lesson: Validate at the boundary. Every place user input enters the system—parser, frontmatter, CLI args—needs explicit limits. The interpreter should never have to wonder whether its input is sane.
Lesson: benchmark your hot paths #
In a live editor, every keystroke runs the full lex→parse→interpret→present loop. Your budget is single-digit milliseconds.
In CalcMark’s TUI, the user types and the preview pane updates in real time. Every keystroke re-evaluates the entire document. That means the full pipeline—lexer, parser, semantic checker, interpreter, formatter—runs on every keypress. A small allocation in the wrong place doesn’t just slow down a batch job; it makes the editor feel sluggish.
Parser benchmarks target < 5μs for simple expressions and < 50μs for multi-line programs. These run in CI, so regressions get caught before they ship.
Fraction arithmetic was one of the first places those benchmarks surfaced a real problem. The interpreter was multiplying fraction denominators as BigInt values without checking their size first. For most fractions that’s fine. But chained operations like 1/7 * 1/13 * 1/17 * 1/19 produce denominators that grow exponentially—and Go was allocating huge BigInt objects on every multiplication.
The fix was a one-line pre-check: before multiplying two fractions, measure how big the resulting denominator would be. If it’s going to be enormous, convert both fractions to decimals first and do regular arithmetic instead. You lose exact-fraction precision, but you avoid allocating a number with thousands of digits on every keystroke.
The lesson: Set performance targets, run them in CI, and let the benchmarks tell you where to look. Most performance wins in an interpreter aren’t algorithmic overhauls—they’re small checks in the right place.
What I’d tell someone starting a language in Go #
Default to ordered data structures. This looks harmless:
1 2 3for name, rate := range frontmatter.Exchange { env.SetExchangeRate(name, rate) }But Go maps randomize iteration order. Your tests pass on Monday and fail on Tuesday. Wrap your maps from day one.
Enforce layer boundaries with tests.
boundary_test.gorunsgo list -jsonand checks that nospec/package imports fromimpl/. Cheap to write, has prevented real mistakes—like the language spec accidentally depending on the interpreter implementation.Silent degradation is your enemy. Most software fails loudly—a missing function throws an error, a bad query returns a stack trace. Language implementations fail quietly. When the classifier doesn’t recognize
1/2as a calculation, it doesn’t crash—it classifies the line as markdown and moves on. Your document renders. Your tests pass. The fraction just isn’t there. Write tests that assert “this input produces this specific output,” not just “this input doesn’t blow up.”Invest in structured output early. CalcMark’s JSON formatter exposes everything:
1 2 3 4 5 6 7 8 9 10 11 12{ "blocks": [{ "type": "calc", "results": [{ "variable": "total", "value": "32.39", "type": "Currency", "currency": "USD", "display": "$32.39" }] }] }When a bug comes in, I run
cm convert -f jsonand immediately see which layer broke. Claude uses it too—paste JSON output into a bug report and it pinpoints the problem without guessing.Reject bad input at the gate. A language that accepts arbitrary user input needs limits. CalcMark’s parser enforces them in
spec/parser/limits.go:1 2 3MaxNestingDepth = 100 // (((((...))))) stack overflow MaxTokenCount = 10_000 // x1+x2+x3+...+x10000 token bomb MaxCompoundPeriods = 10_000 // compound(x, y, 999999) CPU exhaustionThese get checked before parsing starts. We also had a fun one where YAML’s
.nanand.infvalues in frontmatter causeddecimal.NewFromFloat()to panic—a NaN/Inf guard now rejects those at the boundary.Benchmark your hot paths. Language interpreters do the same operations millions of times. We found fraction arithmetic allocating huge
BigIntobjects inside loops. The fix inimpl/interpreter/operators.gowas a pre-check:1 2 3 4// If denominator product would be too large, convert to decimal if leftFrac.Denom().BitLen()+rightFrac.Denom().BitLen() > denominatorBitLenLimit { return evalBinaryOperation(fractionToNumber(leftFrac), fractionToNumber(rightFrac), operator) }Check the size before the allocation, not after. Parser benchmarks target < 5μs for simple expressions and < 50μs for multi-line programs.
Checklists beat architecture diagrams. The 8-layer type checklist and 12-layer expression checklist have prevented more bugs than any design document.
Document the bugs that teach you something. Claude reads them at the start of every session. The same class of bug rarely bites twice.
Conclusion #
Four months ago I didn’t know how to build a language. I still don’t know how to write one—Claude does that. But I know how to design one, and the difference matters more than I expected.
The lessons above aren’t things I read in a textbook. They’re things I learned by shipping broken fractions, debugging non-deterministic tests at 11pm, and staring at autocomplete suggestions that refused to update. Every one of them is documented in a solution doc so the agent doesn’t make the same mistake twice. That’s the real compounding: not writing code faster, but accumulating judgment about what to build and what to watch out for.
CalcMark is open source at github.com/calcmark/go-calcmark. The architecture doc covers the full system. If you’re building something similar, I hope these lessons save you some of the debugging we did.
If you studied CS, these lessons probably sound like week 3 of your compilers course. I didn’t study CS. I’m a practitioner who wanted a language that scratches my own itch and I built one in four months with an AI. If you spot something fundamentally wrong, I’d genuinely love to hear about it—open an issue. If you’re just mad that AI helped me ship something you gatekeep behind a degree, well, I humbly suggest that you get over yourself 😈 ↩︎
Abstract Syntax Tree—the tree-shaped data structure that represents parsed code.
price = 29.99 * 2becomesAssignment{name: "price", expr: BinaryOp{left: Number{29.99}, op: *, right: Number{2}}}. Zero execution logic. Theimpl/layer is how CalcMark runs in Go—expression evaluation, type dispatch, document orchestration. A test inspec/boundary_test.goenforces the boundary: ↩︎