Technology Is Not the Change You Are Managing #
Key lessons #
AI is the technology change of the moment, and like every technology change before it, the technology is not the change being managed. The change is to the systems and behaviors the organization runs on, and AI amplifies whichever ones are already in place—the productive ones along with the dysfunctional ones.12 Teams operating in good systems get faster output; teams in broken systems get more broken output, faster. Quality, as Deming argued, is a property of the system rather than of the individuals working inside it,3 which means the levers are mostly system-level—the scaffolding around the work, not the worker.4 The technical work matters, but the system-level work is where outcomes are determined.
This piece treats ADKAR—Prosci’s five-gate model of individual change—as a diagnostic for the people side of any technology transformation, and uses a data center migration as the worked example because the dynamics are clearer when removed from the noise of the current AI cycle. The takeaways:
- Technology is rarely the change being managed. The trigger gets the attention; the change is to the systems and behaviors the organization runs on. The symptoms of adoption failure—workloads that didn’t move, practices abandoned within a quarter, on-call rotations that quietly revert—don’t appear in the architecture review or the risk register.
- Technology amplifies what’s already there. AI doesn’t reshape organizations; it accelerates whatever operating system they’re already running. Teams that were going to do well will do better, faster; teams that were stuck will get more stuck, faster.
- ADKAR’s five gates (awareness, desire, knowledge, ability, reinforcement) are sequential. A blocked earlier gate stops every later one. You can’t train someone into wanting something they don’t want, and you can’t reinforce a behavior they don’t yet have.
- Each gate has a reflex intervention that’s usually wrong. The most expensive misreading is treating desire problems as awareness problems—running more rationale at people who already understand and just don’t want the change—which hardens resistance rather than addressing it.
- Reinforcement is the gate most often dropped at the technical cutover. Migrations that don’t make decommissioning a real, dated milestone drift back to old patterns within a quarter, and that drift is what makes the next change harder to land.
- ADKAR’s contribution is diagnostic, not prescriptive. Its value is forcing the question “which gate is actually blocked?” before reaching for whatever intervention is closest at hand. It’s the individual-level complement to Kotter and Lewin, not a substitute.
Change management #
Change management addresses what project management doesn’t: the human side of getting a change to take hold. Large change programs have two ways to fail that look identical from a distance—the technical work didn’t get done, and the technical work got done but nobody used the result. Project management is built to prevent the first; change management addresses the second.
The discipline has several frameworks operating at different layers. Lewin’s three-step model—unfreeze, change, refreeze—frames change at the organizational level as a shift between equilibria.5 Kotter’s eight-step model is broader, treating change as a leadership problem from establishing urgency through anchoring change in culture.6 Prosci’s ADKAR is narrower and individual: how single people move through a change. The frameworks aren’t competing; they operate at different scales, and serious programs use them together—Kotter for the organizational story, ADKAR for the individual diagnosis.
ADKAR as a specific framework #
ADKAR comes out of Prosci’s research into what determines whether organizational change takes hold.7 The premise: organizational change is the sum of individual changes, and individuals move through five gates in a fixed order. A blocked gate stops the change there regardless of how good the next one looks—you can’t train someone into wanting something, and you can’t reinforce a behavior they don’t yet have. The model’s value is diagnostic: it tells you which gate is actually blocked, so you can apply the right intervention rather than the most familiar one.8
The five gates:
| Gate | The question | What it requires |
|---|---|---|
| Awareness | “Why is this happening?” | Understanding the business reasons, risks of not changing, and personal impact |
| Desire | “Do I want this?” | Personal motivation, addressing what’s in it for them, feeling heard |
| Knowledge | “How do I do this?” | Training, documentation, practical skills |
| Ability | “Can I do it under real conditions?” | Practice, coaching, time to develop proficiency |
| Reinforcement | “Will I keep doing it?” | Recognition, accountability, sustained commitment |
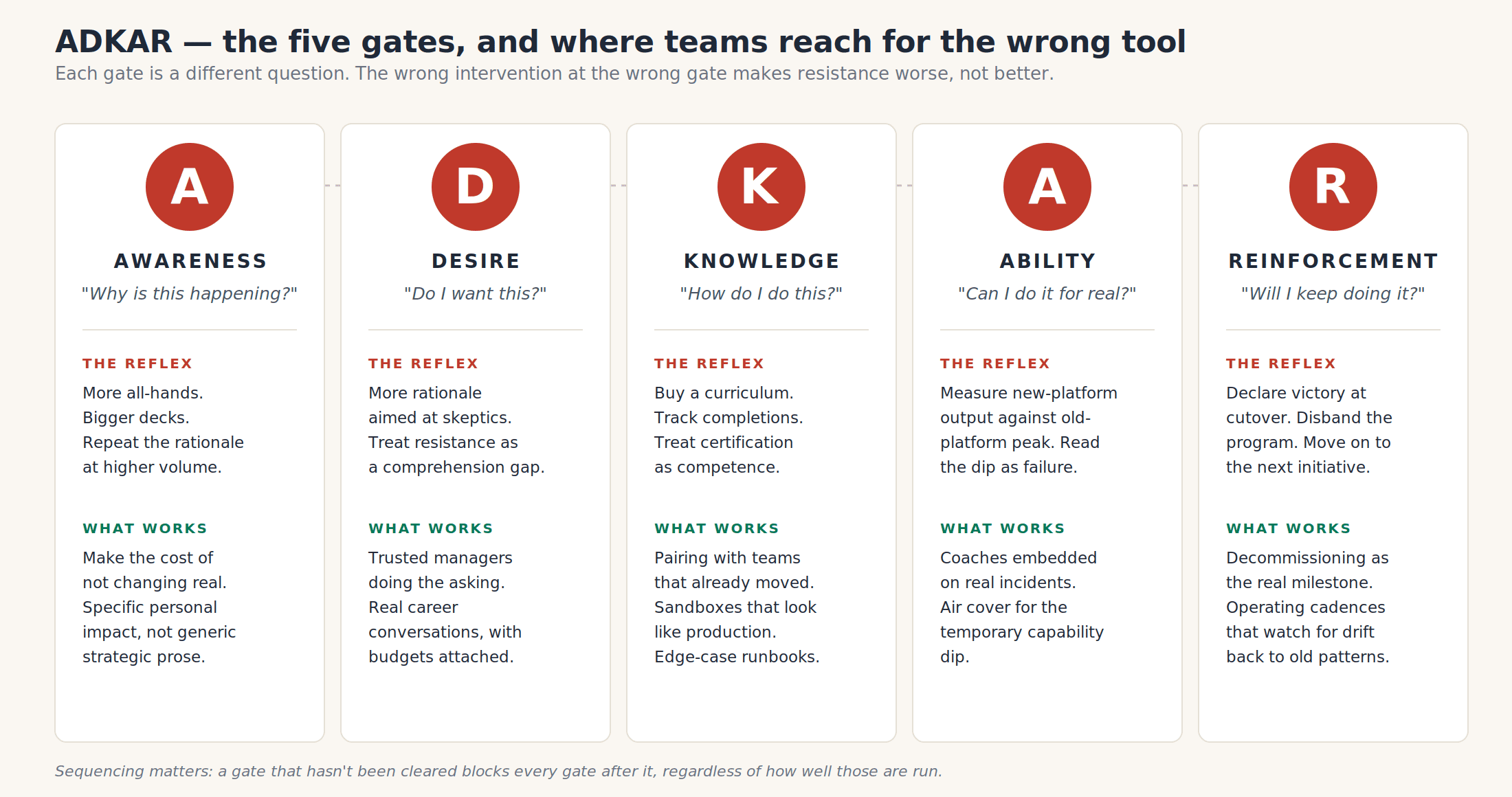
The diagram below shows the diagnostic shape: the question at each gate, the intervention most leadership teams reach for, and the intervention that actually moves people through.

The five gates, the reflex at each one, and what actually moves people through.
The scenario #
A mid-sized SaaS company is migrating its primary production workloads from a colocated facility to a public cloud over eighteen months. Several pressures combined:
- The colo lease is up in two years, with renewal terms worse than what the company signed at five years ago.
- Capacity is tight: hardware orders run months behind the product roadmap.
- Recovery from regional outages is slow and largely manual, with a runbook that depends on a small group of senior engineers being awake.
- The product roadmap depends on faster geographic expansion than the current footprint can support without significant capital outlay.
No single reason is decisive; together they make the do-nothing option clearly worse.
Multiple teams and roles are involved, each with their own accountabilities and reasons to want or to resist the change:
- The infrastructure team that owns the physical and platform layer today, with deep operational expertise that’s partly platform-specific and partly built up over years.
- The platform engineering team building the cloud landing zones, accountable for the new platform working at scale and earning the trust of the application teams.
- The application teams (around a dozen) that have to move their services while still shipping product.
- Security, because the network and identity primitives are different and the controls have to be reimplemented.
- Compliance, because the audit evidence shape changes and the old artifacts don’t transfer cleanly.
- Finance, because metered consumption is a different operational discipline than capital depreciation, and the spend forecasting model is new.
Roughly eighty engineers are touched, plus the supporting functions—each viewing the migration from a different vantage point.
Awareness #
Why is this happening?
The problem. Awareness is the easiest gate to think you’ve cleared, because the work products are visible: announcement decks, town halls, FAQs. Most leadership teams treat the announcement as having built awareness; the announcement is when awareness work starts. Awareness in the ADKAR sense isn’t “the message has been sent” but “the people affected understand the business reasons, the consequences of not changing, and what it means specifically for them.” That last part—for them—is the part that usually doesn’t get done, because it requires conversations, not communications.9
For a data center migration, real awareness means surfacing what isn’t in the announcement deck:
- The cost picture, with actual numbers. What the colo lease and depreciation look like over the next three years, side by side with the migration cost picture.
- The strategic shift in concrete terms. What faster outage recovery is actually worth, what elasticity makes possible, what the geographic expansion the company keeps talking about actually depends on.
- The personal impact for each role. What changes for an SRE’s on-call experience, what an application team’s deploy pipeline looks like in twelve months, what this means for the on-prem expert of six years now told their expertise is depreciating.
The reflex. When awareness seems shaky, the instinct is more all-hands, bigger decks, repeating the rationale at higher volume. Volume isn’t the variable. If the rationale didn’t stick the first time, repeating it doesn’t help—and more rationale-broadcasting pushes the problem into the next gate, where it gets misdiagnosed as a desire or knowledge problem.
What actually works. Sustained, specific conversation, not communication. People who genuinely have awareness can explain the rationale to each other in their own words, including the uncomfortable parts—some teams will be reorganized, some skills will depreciate, the lease really is up. The work happens through middle managers having structured conversations with their teams. The other useful move is making the do-nothing option concrete: showing the actual cost picture three years out, side by side with the migration cost, so the change isn’t “leadership wants this” but “the alternative is visibly worse.”
Desire #
Do I want this?
The problem. Desire is where most migrations stall, and it’s the gate leadership teams are least equipped to address—it can’t be solved with a memo or a training program. Desire is personal: it’s shaped by trusted relationships, credible incentives, and whether people feel heard.10 A few archetypes recur:
- The senior infrastructure engineer who owns the current platform. They built much of what’s running today. The migration threatens their expertise, and the standard response—“you’ll learn the new platform”—misses the point. What they’re worried about is status, identity, and whether their judgment will still be trusted in twelve months.
- The SRE team with years of institutional knowledge. The runbooks in their heads, the intuition for which alerts are real, the relationships with the rare network engineer who knows the obscure subsystem—none of that transfers cleanly. Being asked to give it up for the cloud team’s standard playbook can feel like having competence taken away.
- Application teams that don’t trust the platform team yet. They’ve been told the new platform will give them better deploys and observability; they’ve been told that before. The default is wait-and-see, which manifests as foot-dragging.
- Security and compliance teams worried about being steamrolled. A velocity-driven migration is exactly where their concerns get treated as friction. If they sense that, they will become the friction on purpose, because it’s the only lever they have.
The reflex. Escalate awareness: assume people don’t yet understand the rationale, run more rationale-focused communications. This usually makes resistance worse. People who already understand and don’t want the change interpret another rationale deck as evidence that nobody is listening, and their resistance hardens.
What actually works. Desire moves through trusted people doing the asking, real conversations about what changes for individuals, and genuine input on the plan. Direct managers and trusted senior engineers move desire far more than VPs or all-hands speakers; the most consequential move leadership has is making sure those middle managers actually believe in the change themselves, because their teams will read them in five minutes regardless of the official messaging. Real career conversations—“you’re going to be the cloud platform tech lead, here’s what that role looks like in eighteen months, here’s the budget for training and conferences”—move desire in ways no all-hands can. Visible input on the plan from the people who will execute it shifts the conversation from compliance to ownership. Honest acknowledgment of what’s being given up is more durable than pretending nothing is being lost.11
Knowledge #
How do I do this?
The problem. Knowledge is the gate technology organizations over-invest in. Training programs, certifications, and documentation portals are easy to buy, easy to count, and produce visible motion. Their legibility makes it tempting to use knowledge work to substitute for awareness and desire work, which it cannot do. Trained-but-unwilling people don’t apply what they’ve learned.
When people are ready to learn, what they need for a cloud migration is more specific than generic platform training:
- Platform fundamentals applied to the company’s actual architecture. The landing zones the platform team has chosen, the patterns adopted internally, the way services here actually get deployed—not the abstract reference architecture from a vendor course.
- The new observability and incident response model taught as habits. What dashboards to check, what an alert means in the new world, how to triage without the on-prem context engineers have built up.
- Cost management discipline. Metered consumption is a different operational craft than capital-budgeted capacity, and engineers who haven’t worked in a metered environment don’t develop the instinct without practice.12
- Updated security and compliance patterns taught alongside the platform. The model for network segmentation, secrets handling, and audit evidence changes meaningfully; bolting these on after platform training is too late.
The reflex. Buy a curriculum, dump it on engineers, treat completion as competence. This produces metrics that look like progress—courses completed, certifications earned—without producing engineers who can run a service in the new environment. The downstream symptom shows up at the next gate, where ostensibly trained engineers can’t function under real conditions.
What actually works. Pair engineers with people who have already done the work. Internal storytelling beats vendor training: an hour with the team that migrated last quarter is worth more than days of generic course material. Sandbox environments that look like production let engineers break things without consequences. Runbooks for the messy edges—the weird incident, the partial outage, the cost spike at quarter-end—are far more valuable than happy-path documentation.
Ability #
Can I do it under real conditions?
The problem. Ability is the gap between knowing how something is supposed to work and being able to make it work when it matters. It’s the most underestimated gate in technical migrations because the symptoms look like knowledge problems but they aren’t. Engineers who can pass the certification still freeze when production is on fire at three in the morning, because the alerts mean different things, the mental model isn’t yet automatic, and operator instincts that took years to build are temporarily mediocre. This isn’t a curriculum failure; it’s the cost of building real ability.13
The ability gate manifests in predictable ways:
- The first few application migrations are slow and painful, even with strong teams. Treating that as failure—measuring new-platform productivity against old-platform peak—forces teams to fake competence rather than build it.
- On-call in the new environment feels different even with full training. Alert fatigue lands differently when underlying systems are unfamiliar.
- Performance characteristics surprise everyone. Things that ran fine in the colo behave oddly in the cloud, and figuring out why takes time.
These aren’t productivity losses to be eliminated; they’re the cost of building competence.
The reflex. Measure productivity in the new environment against the old environment’s peak, declare a problem, escalate. This triggers one of two bad responses: teams hide problems until they accumulate into a real incident, or leadership starts second-guessing the migration and everyone loses confidence. Both make things worse.
What actually works. Pilot teams with disproportionate support. The first few teams to migrate carry the organization’s learning—staff them well, give them senior coaching, protect them from output measurement during the transition. What they’re producing is institutional capability, not features. Pair on first real incidents: a senior engineer riding along on the first few new-environment incidents teaches more than weeks of training. Air cover from leadership during the dip is non-negotiable. To diagnose whether a team is through this gate, ask whether they can do the work without supervision under steady-state conditions. If no, more documentation isn’t the lever—more practice is.
Reinforcement #
Will I keep doing it?
The problem. Reinforcement gets forgotten in technology migrations because the technical work feels like it has a clear endpoint. The last service moves over, the success email goes out, the program team gets reassigned, and people drift back toward old patterns within a quarter. The migration looks like it succeeded—cutover happened, announcement sent, program closed—but the durable change required to actually realize the value never happened, and three years later the company is paying for a cloud platform mostly running cloud-hosted versions of the old architecture.
A migration without reinforcement produces three failure modes:
- Lift-and-shift drift. Services rewritten to be cloud-native quietly accrete old patterns over time, because that’s how engineers think and there’s no one holding the line.
- Shadow on-prem. The old environment is officially decommissioned, but a few critical workloads, a forgotten database, and a couple of jump hosts are still running because nobody got around to moving them. They keep running for years, getting more brittle.
- Reverted operating practices. The new on-call model, deployment cadence, and cost reviews were set up during the migration. Six months later, half are quietly abandoned because nobody is pushing on them.
The reflex. Declare victory at the technical cutover, congratulate the team, disband the program. This is satisfying for everyone involved and produces no information about whether the change is durable—because the period that determines durability is the six to eighteen months after cutover, when the program is no longer running and people are quietly deciding whether to maintain the new patterns or revert.
What actually works. Make decommissioning a real, dated milestone. Until the old data center is shut down and the lease signed off, the migration isn’t done; people with one foot in both worlds will keep one foot in both worlds. Recognize “migrated and decommissioned” differently from “migrated”—the cleanup is what makes the change durable. Build the new patterns into the operating cadence: cost reviews, architecture reviews, and on-call rotations structured around the new platform. A simple quarterly question at a leadership review—“what’s still running on the old patterns?”—surfaces drift before it calcifies.
The reinforcement gate of this migration is partially the awareness and desire gates of whatever comes next. A company that lets a migration drift back has trained its people that announcements don’t mean follow-through, which makes the next change harder regardless of how well it’s planned.
Diagnosing where you’re stuck #
ADKAR is most useful in flight as a diagnostic. When the migration is moving slowly or a particular team is dragging, the model lets you ask which gate is actually blocked rather than reaching for the closest intervention. Patterns to recognize:
| What you’re seeing | Most likely barrier | What probably won’t help |
|---|---|---|
| Teams keep asking “why are we doing this again?” months in | Awareness—the rationale hasn’t landed | More training |
| People nod in meetings and quietly drag their feet | Desire—concerns aren’t being heard | More rationale decks |
| Engineers repeatedly ask the same basic platform questions | Knowledge—training didn’t cover their actual work | More town halls |
| Trained engineers struggle on real production incidents | Ability—they need practice and coaching, not docs | More documentation |
| Migrated teams quietly revert to old patterns | Reinforcement—no ongoing operating mechanism | More retrospectives on the migration itself |
The temptation in each case is to apply the intervention you have most readily—usually more communication or more training—regardless of what the actual block is. ADKAR’s contribution is slowing that reflex long enough to ask the right diagnostic question first.
What ADKAR is and isn’t #
ADKAR is the human layer underneath a technical change—not a substitute for a sound migration plan, a risk register, a financial model, or a clear technical architecture. You can’t ADKAR your way out of a bad technology decision; a beautifully-run change management program on top of a flawed plan produces a well-adopted failure.
What ADKAR does is give you a model for the part of the work that doesn’t show up in the architecture diagram or the project plan. For any real migration, that’s both what determines outcomes and what’s missing from most program plans, because it has no obvious owner. Naming the gates and assigning the work of moving people through each one is the change management contribution to the program.
The same reasoning applies to whatever technology change comes next. The immediate one is AI. The hardest part of an AI rollout will not be the technology—vendors will compete to make that easier. It will be the systems-and-behaviors layer underneath, where workflows have to change, decisions have to be made differently, and the temporary capability dip of real ability-building has to be absorbed. Organizations that have done that work well before will do it well again, faster than the technology can deliver. Organizations that have not will discover that the technology amplifies what’s already there, and that the gates are the same ones they didn’t clear last time.
References #
A note on sources. ADKAR® is a registered trademark of Prosci, Inc., and Kotter’s eight-step model is the published work of Kotter International. Everything here is drawn from publicly available material—Hiatt’s 2006 book, Prosci’s methodology pages and research blog, Kotter’s and Lewin’s published work, and the third-party explanations linked above—and discussed as commentary under fair use. No proprietary materials are reproduced; the diagram is hand-authored for this post.
DX. “Designing the AI-native engineering organization.” Argues that AI’s effect on engineering output is gated by the strength of the existing operating system: organizations with mature delivery practices compound their advantage with AI; organizations without those foundations see existing dysfunction surfaced and accelerated rather than fixed. https://newsletter.getdx.com/p/designing-the-ai-native-engineering ↩︎
Matusov, Lizzie. “RDEL #141: How can engineering leaders prepare their teams for AI?” Research-Driven Engineering Leadership. Surveys research on AI’s impact on engineering team performance, with the consistent finding that variance in outcomes between teams adopting the same AI tools is large and is driven primarily by team-level practices rather than tool selection. https://rdel.substack.com/p/rdel-141-how-can-engineering-leaders ↩︎
Deming, W. Edwards. Out of the Crisis (1986), MIT Press. Deming’s argument that the overwhelming majority of variation in outcomes comes from the system rather than the individuals working in it (the often-quoted “94/6” claim) is foundational to the systems-quality view this piece takes. See also my own post applying Deming’s lens to modern software organizations: “Systems, not individuals, determine product quality”. https://mitpress.mit.edu/9780262541157/out-of-the-crisis/ ↩︎
Osmani, Addy. “Agent skills.” Argues that the scaffolding around an agent is critical to AI-driven engineering quality precisely because it encodes proven human behavior into the system rather than relying on the individual operator to reproduce it each time. A contemporary illustration of the Deming view that quality is a property of the system rather than the worker. https://addyosmani.com/blog/agent-skills/ ↩︎
Lewin, Kurt. “Frontiers in Group Dynamics: Concept, Method and Reality in Social Science; Social Equilibria and Social Change.” Human Relations, 1(1), 1947. The original three-step (unfreeze, change, refreeze) model that anchors much of subsequent change management theory. https://journals.sagepub.com/doi/10.1177/001872674700100103 ↩︎
Kotter, John P. Leading Change (1996), Harvard Business Review Press. Kotter’s eight-step model addresses change at the organizational and political level, and is the most useful complement to ADKAR’s individual-level diagnosis. https://www.kotterinc.com/methodology/8-steps/ ↩︎
Hiatt, Jeffrey M. ADKAR: A Model for Change in Business, Government, and Our Community (2006), Prosci Learning Center Publications. The foundational text introducing the five-element model and the premise that organizational change is the sum of individual changes. https://www.prosci.com/resources/articles/what-is-the-adkar-model ↩︎
Prosci. The Prosci ADKAR Model (overview and methodology). The clearest current statement of the model’s diagnostic application—using ADKAR to identify a person or group’s barrier point and apply the intervention specific to that gate. https://www.prosci.com/methodology/adkar ↩︎
Prosci. Best Practices in Change Management (recurring biennial research report). The longitudinal Prosci research consistently finds that “ineffective communication”—a substitute for awareness work—is among the top reasons change initiatives miss their goals. https://www.prosci.com/blog/top-contributors-to-change-management-success ↩︎
Sirkin, Harold L., Keenan, Perry, & Jackson, Alan. “The Hard Side of Change Management.” Harvard Business Review, October 2005. Sirkin et al. argue that the “hard” factors that determine outcomes—duration, integrity, commitment, effort—are usually neglected in favor of the softer cultural work, and that resistance leadership reads as cultural is often a rational response to incentives that haven’t been adjusted. https://hbr.org/2005/10/the-hard-side-of-change-management ↩︎
Heath, Chip & Heath, Dan. Switch: How to Change Things When Change Is Hard (2010), Crown Business. Their elephant/rider/path framing maps closely to awareness/desire/knowledge, and their core insight that you have to “shape the path”—change the environment, not just the messaging—is the same point ADKAR makes about desire being moved through structural change rather than communication volume. ↩︎
FinOps Foundation. FinOps Framework and associated practitioner materials. The discipline of operating in a metered cloud environment as a craft distinct from capital-budgeted infrastructure operations. https://www.finops.org/framework/ ↩︎
Forsgren, Nicole, Humble, Jez, & Kim, Gene. Accelerate: The Science of Lean Software and DevOps (2018), IT Revolution Press. The DORA research underlying Accelerate documents the temporary capability dip teams experience adopting new practices, and the finding that performance recovers and exceeds the prior baseline when leadership absorbs the dip rather than treating it as failure. See also DORA’s ongoing reports at https://dora.dev. ↩︎