March 31, 2021
datascience
Pangeo
I’m researching a variety of open source approaches and tools to support large scale scientific modeling and the data issues that come with it. Think multi-TB model outputs, and standardized formats like netCDF.
Nate told me about Pangeo from his time at NCAR. I read a boatload of docs and watched a great introductory video from 2018.
Reasons
Problems it solves are:
- Common data model for accessing data science-y/geosciene-y data like netCDF, GeoTIFF, and more.
The use of Zarr is interesting here as a R/W option for
$X$array. - Moving compute and simulation (the running of numerical models) closer to the data, which at this point is too big to move.
- Ties to the existing data science toolkit, e.g., Python, NumPy, Dask. One element of the work is to move lots of data from machines in a cluster spitting out model output (think SAN or even attached SSD), and get it somewhere more useful for downstream scientists and other users.
Pangeo Forge
One of the issues to solve is how to transform data from formats like netCDF into Zarr in a more pre-defined way. Turns out that the Pangeo team have a new project roadmap defined for Pangeo Forge.
It takes the guesswork out of ETL for earth science data using an approach similar to ‘recipes’ used in Conda Forge. This diagram really says it all (source):
{kind=link}
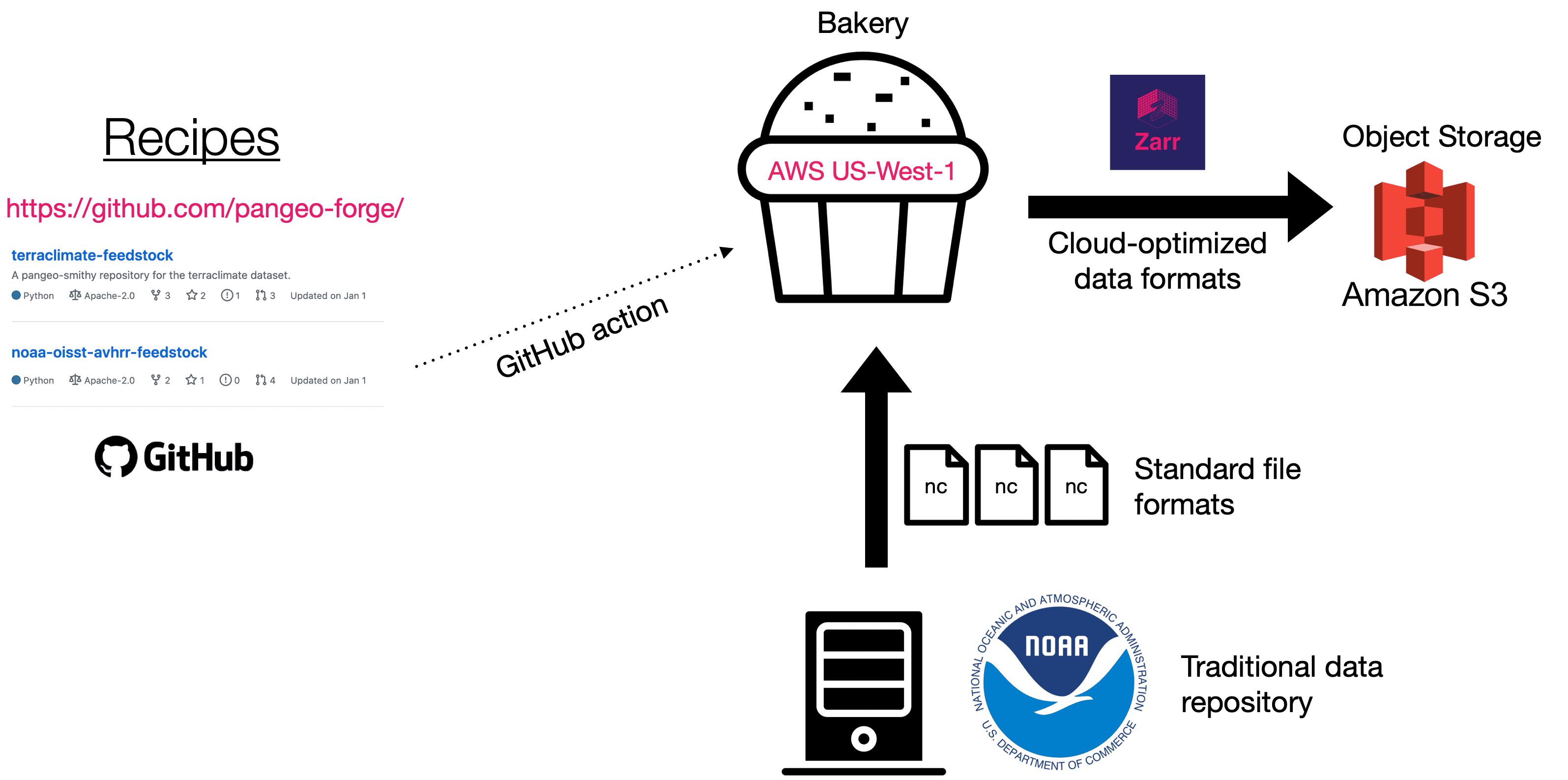
Earth science data reciples with Pangeo Forge
Prefect
Looking around the source code I saw that Pangeo Forge will be using a project called Prefect. It’s highly reminiscent of Apache Airflow in terms of workflow definition and execution. And then it becomes really clear that the Prefect folks know and love Airflow a lot, but have reasons for not using it.
“…Airflow’s applicability is limited by its legacy as a monolithic batch scheduler aimed at data engineers principally concerned with orchestrating third-party systems employed by others in their organizations.”
Intrigued that the deployment story is to a Dask cluster or via Kubernetes. I’ll not dig in unless I need to, but happy to find another modern DAG-based workflow automation system/platform/tool.